개요
그래프란 정점과 간선으로 구성된 자료구조로, 버스 노선 설계와 같은 생활속 문제부터 다양한 학술 분야의 이론까지 폭넓게 도입할 수 있다.
트리란 그래프의 일종으로 사이클이 없으며 연결성을 가진다는 강력한 조건을 가져 알고리즘 설계에 자주 사용된다.
본 글은 수열에서 특정 조건을 만족하는 순서쌍의 개수를 세는 복잡한 쿼리를, 트리를 활용하여 효율적으로 처리하는 새로운 알고리즘을 소개한다.
본문은 아래의 내용을 부가적인 설명 없이 서술한다. 각 항목에 대하여 자세하게 서술한 좋은 글을 링크해두었다.
- 세그먼트 트리 (Segment Tree)
- Heavy-Light Decomposition (HLD)
- 좌표 압축 기법 (Coordinate Compression)
- 제곱근 분할법 (Sqrt Decomposition)
문제 제기
수열 쿼리 문제
다음과 같은 문제를 생각하자.
길이 $N$의 수열 $A = \left\{ A _1, A _2, \cdots, A _N \right\}$가 주어진다.
아래와 같이 두 종류의 쿼리가 존재한다:
- $1 \le i \le N$과 $x$가 주어진다. $A _i$의 값을 $x$로 변경한다.
- $1 \le i < j \le N$과 $ \max \left\{ A _{i+1}, A _{i+2}, \cdots, A _{j-2}, A _{j-1} \right\} < A _i = A _j $을 모두 만족하는 순서쌍 $(i, j)$의 개수를 센다.
$Q$개의 쿼리가 주어진다. 이 쿼리를 순차적으로 처리할 때, 2번 쿼리에 대한 답을 반환하라.
2번 쿼리는 다음과 같이 해석할 수 있다:
$N$개의 전봇대가 일렬로 배열되어 있으며, $i$번째 전봇대의 높이는 $A _i$이다.
다른 전봇대와 교차하지 않도록 두 전봇대 $i$, $j$ 사이에 전선을 놓을 수 있을 때, 그러한 순서쌍 $(i, j)$의 개수를 세어라.
예제
$N = 6$, $A = \left\{ 2, 1, 1, 2, 3, 2 \right\}$라고 하자.
$Q = 5$개의 쿼리가 순서대로 [“2번 쿼리”, “1번 쿼리, $i = 5$, $x = 2$”, “2번 쿼리”, “1번 쿼리, $i = 2$, $x = 3$”, “2번 쿼리”]라고 하자.
먼저, $(1, 4)$과 $(2, 3)$, 두 개의 순서쌍이 2번 쿼리의 조건을 만족하므로, 첫 번째 쿼리의 답은 $2$이다.
두 번째 쿼리에 의하여 $A _5 = 2$가 되었고, $A = \left\{ 2, 1, 1, 2, 2, 2 \right\}$이다.
이제, $(1, 4)$, $(2, 3)$, $(4, 5)$, $(5, 6)$의 순서쌍이 조건을 만족한다. 따라서, 세 번째 쿼리의 답은 $4$이다.
네 번째 쿼리는 $A _2$의 값을 $3$으로 변경한다. $A = \left\{ 2, 3, 1, 2, 2, 2 \right\}$.
마지막 쿼리의 답은, $(4, 5)$과 $(5, 6)$만 조건을 만족하므로, $2$이다.
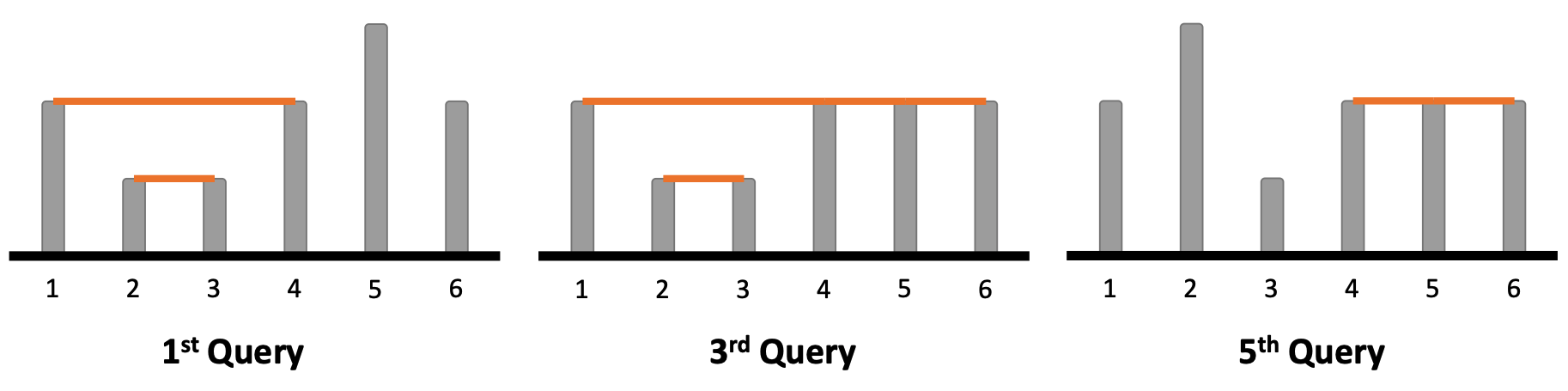
그림 1: 예제의 시각화
회색 기둥은 전봇대를, 주황색 선은 전선을 의미한다.
가장 단순한 접근
2번 쿼리를 빠르게 해결하는 가장 단순한 알고리즘을 찾아보자.
먼저, 모든 $\displaystyle \frac{N \times (N-1)}{2}$개의 순서쌍 $(i, j)$에 대하여 부등식 조건을 만족하는지 선형 시간 $O(j-i+1)$에 확인하면, 하나의 쿼리를 $O \left( N^3 \right)$에 해결할 수 있다.
세그먼트 트리 등의 자료구조를 이용하여 구간의 최댓값을 $O \left( \lg N \right)$에 답할 수 있다면, 시간 복잡도를 $O \left( N^2 \lg N \right)$까지 낮출 수 있다.
$i$를 고정한 후, $j$를 점차 증가하면서 구간 $[i+1, j-1]$의 최댓값을 잘 관리해주면, 시간 복잡도를 $O \left( N^2 \right)$로 개선할 수 있다.
이제 다음과 같은 중요한 관찰이 필요하다.
각 $j$에 대하여, 순서쌍 $(i, j)$가 부등식 조건을 만족하는 그러한 $i$는 많아야 한 개 존재한다.
그러한 $i$가 두 개 이상 존재하면, 제일 작은 $i$에 대하여 순서쌍 $(i, j)$는 부등식 조건을 만족할 수 없다.
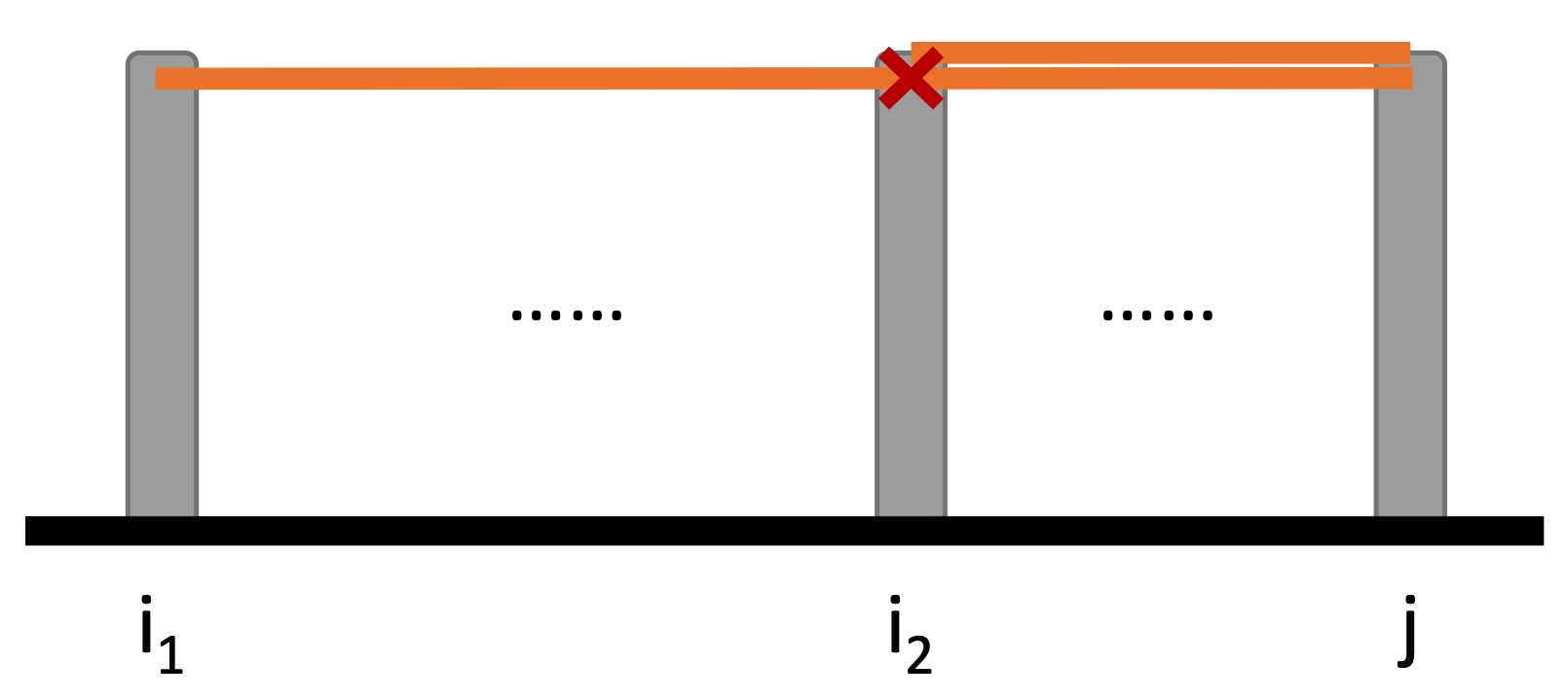
그림 2: 첫 번째 관찰의 모식도
$\left( i_1, j \right)$과 $\left( i_2, j \right)$는 모두 조건을 만족하는 순서쌍이 될 수 없다.
$i < j$이고 $A _i \ge A _j$라면, 모든 $i’ < i$에 대하여 순서쌍 $(i’, j)$는 부등식 조건을 만족할 수 없다.
구간 $[i’ + 1, j - 1]$의 최댓값이 이미 $A _i$ 이상이고, 이는 $A _j$ 이상이므로, 이 관찰은 성립한다.
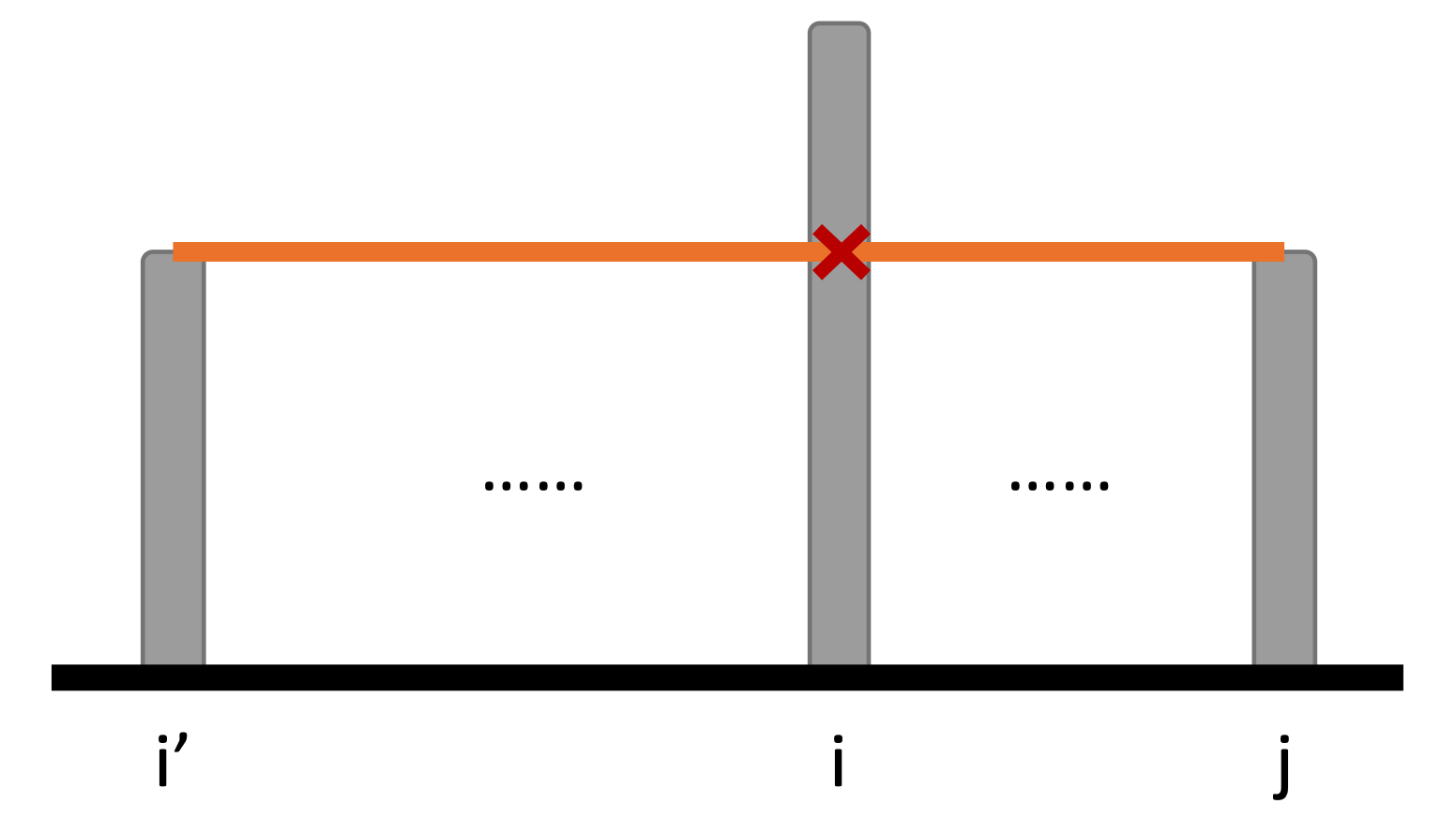
그림 3: 두 번째 관찰의 모식도
$A _i$가 이미 $A _j$ 이상이므로, $\left( i', j \right)$는 조건을 만족하는 순서쌍이 될 수 없다.
위의 관찰은 우리에게 스택을 활용한 알고리즘을 제시한다.
먼저, $j$를 $1$부터 $N$까지 증가하면서, 어떤 $j’ \ge j$에 대하여 순서쌍 $(i, j’)$가 부등식 조건을 만족할 ‘가능성’이 있는 모든 $i$를 스택으로 관리하자.
전봇대 표현을 빌리자면, $j$번 전봇대에서 앞쪽을 바라보았을 때 보이는 모든 전봇대의 번호를 스택이 순서대로 가지고 있는다.
이때, $j$가 증가함에 따라 스택을 쉽게 관리할 수 있으며, 스택을 통하여 조건을 만족하는 순서쌍 $(i, j)$를 쉽게 찾을 수 있다.
이에 대한 자세한 방법은 아래의 코드로 제시한다:
1 | |
$1$부터 $N$까지 $N$개의 수는 스택에 오직 한 번 삽입되고, 한 번 삭제된다.
따라서, 2번 쿼리 당 시간 복잡도는 $O \left( N \right)$이며, 전체 시간 복잡도는 $O \left( NQ \right)$이다.
또한, 부등식 조건을 만족하는 순서쌍은 많아봐야 $N-1$개임을 알 수 있다.
이제, 2번 쿼리를 $O \left( N \right)$보다 빠르게 처리하는 방법을 알아보자.
문제에 대한 첨언
부등식 조건에서 등호 조건 $A _i = A _j$만 있다면, 값이 같은 수의 개수만 관리해주면 되기에 문제가 상당히 쉬워진다.
아래와 같이 C++의 std::map, Python의 dict을 활용하면, 1번 쿼리를 $O \left( \lg (N+Q) \right)$, 2번 쿼리를 $O(1)$에 처리할 수 있다.
1 | |
부등식 조건은 그 자체로도 상당히 다루기 어렵다. 구간의 양 끝 값이 같아야 한다는 ‘점 조건’과 구간의 최댓값이 양 끝 값보다 작아야 한다는 ‘구간 조건’이 같이 있으며, 두 조건을 서로 분리할 수 없기 때문이다.
단 한 번의 1번 쿼리 만으로도 부등식 조건을 만족하는 순서쌍을 $O \left( N \right)$개 변화시킨다.
$N = 2K + 1$, $A = \left\{ K, K-1, \cdots, 2, 1, 0, 1, 2, \cdots, K-1, K \right\}$인 경우, $A _{K+1}$의 값이 무엇이냐에 따라서 순서쌍의 개수가 $0$부터 $K+1$까지 변화할 수 있다.
이는 곧, 조건을 만족하는 순서쌍을 효율적으로 관리하기 어려울 것임을 암시한다.
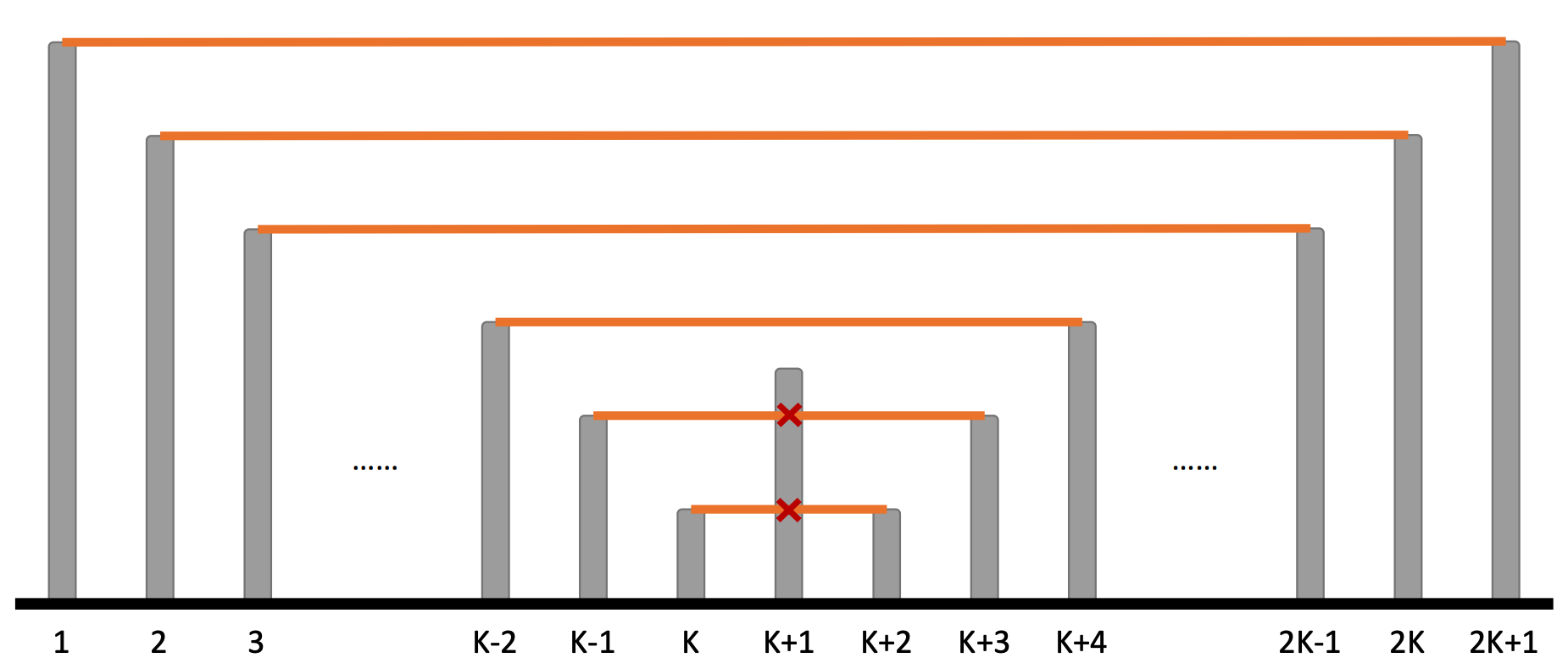
그림 4: 답이 급격하게 변하는 경우
$A_{K+1}$의 값에 따라서 답이 $0$부터 $K+1$까지 가능하다.
문제 해결
연속한 2번 쿼리는 항상 같은 답을 가진다.
따라서, 이제부터는 쿼리를 $(i, x)$로 표현하자. 이는, 1번 쿼리 $(i, x)$와 2번 쿼리를 합쳐 놓은 표현법이다.
즉, 하나의 쿼리는 “값 변경”과 “순서쌍 개수 세기”를 순서대로 수행하여야 한다.
트리 모델링
전봇대 표현을 사용하자.
부등식 조건을 만족하는 모든 순서쌍 $(i, j)$에 대하여, $i$번 전봇대와 $j$번 전봇대 사이에 전선을 선분으로 표현하자.
$A _0 = A _{N+1} = \infty$로 한 후, $(0, N+1)$ 또한 조건을 만족한다고 하자. 각 선분을 정점으로 생각하면, 이들이 하나의 트리를 형성하는 것처럼 보인다.
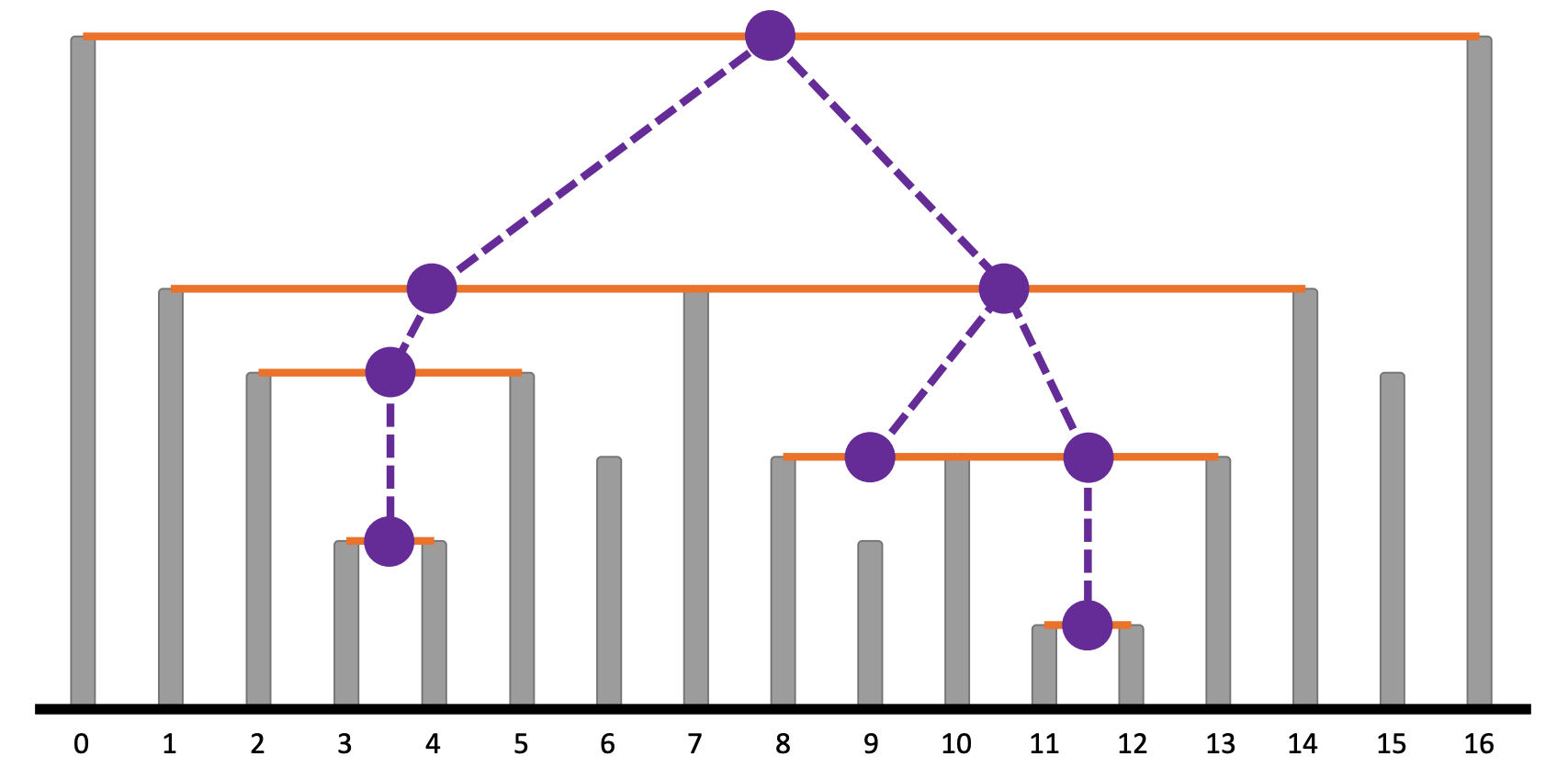
그림 5: 전선의 트리화
보라색 원은 정점을, 보라색 점선은 간선을 의미한다. 전선이 하나의 트리를 형성한다.
이러한 추측은 참이다. 조건을 만족하는 순서쌍은 항상 서로 포함 관계에 있거나, 아니면 교집합을 가지지 않는다. 즉, Laminar set family를 이룬다.
Laminar set family에서 포함 관계를 가장 단순한 형태의 그래프로 표현하면, 여러 개의 트리로 이루어진 Forest가 된다.
여기서는 $(0, N+1)$가 하나의 원소이므로, 우리가 원했던 대로, 하나의 트리를 형성한다.
매 쿼리에 의하여 $A _i$의 값이 변화하면 트리 또한 바뀔 수 있다. 우리는 알고리즘의 효율성을 위하여 트리를 고정할 필요가 있다.
$Q$개의 쿼리에 의하여 한 번이라도 높이($A _i$의 값)가 변화하는 전봇대를 ‘가변 전봇대’라고 부르자. 그렇지 않은 전봇대는 ‘불변 전봇대’이다.
$O \left( Q \right)$개의 가변 전봇대를 모두 무시한 채로, $O \left( N \right)$개의 불변 전봇대에 대해서 위와 같이 트리를 만들자.
여기서 확실한 점은 다음과 같다:
- 전선으로 연결 가능한 두 불변 전봇대 쌍은 모두 트리의 정점 중 하나이다.
- 전선으로 연결 가능한 두 가변 전봇대 쌍 혹은 불변-가변 전봇대 쌍은 트리로 알아낼 수 없으며, 매 쿼리마다 새롭게 세어줄 필요가 있다.
이제, 가변 전봇대를 고려할 때, 트리의 어떤 정점만이 실제로 가능한지를 생각해보자.
그림과 같이, 하나의 가변 전봇대는 이와 교차하는 몇 개의 트리 정점을 ‘비활성화’한다고 생각할 수 있다.
또한, 비활성화되는 그러한 모든 정점은, 자식부터 조상으로 올라가는 하나의 경로로 표현될 수 있다.
따라서, 다음을 효율적으로 처리할 수 있다면, 전선으로 연결 가능한 두 불변 전봇대 쌍의 개수를 셀 수 있다:
- 초기에, 트리의 모든 정점의 가중치는 $0$이다.
- 자식에서 조상으로 올라가는 경로가 주어질 때, 그 경로 위에 존재하는 모든 정점의 가중치를 $1$ 증가 혹은 감소시킨다. 단, 정점의 가중치가 음수가 되지 않음이 보장된다.
- 가중치가 정확하게 $0$인 정점의 개수를 센다.
정점의 가중치가 항상 $0$ 혹은 양수라는 강력한 조건 덕분에, Heavy-light decomposition을 이용하여 각 작업을 $O\left( \lg^2 N \right)$에 처리할 수 있다.
각 체인을 세그먼트 트리로 관리하며, 각 구간에서 가중치의 최솟값과 그러한 값을 가지는 정점의 개수를 관리하면 된다.
1 | |
전선으로 연결할 수 있는 두 가변 전봇대 쌍과 불변-가변 전봇대 쌍은, 위에서 논의한 스택 알고리즘을 조금만 변형하면 $O \left( Q \lg N \right)$에 해결할 수 있다.
$A _i$의 절대적인 값보다는 값의 상대적인 순서가 중요하기에, 좌표 압축 기법을 적용한다면, $O \left( N \lg N \right)$의 전처리로 복잡도를 $O \left( Q \right)$까지 낮출 수 있다.
정리하면, 전처리 작업으로
- $O \left( N \lg N \right)$에 좌표 압축 기법을 적용하고
- 스택 알고리즘을 이용하여 모든 트리 정점을 $O \left( N \right)$에 찾고
- Union-find 혹은 Line sweeping, 스택 등 다양한 방법으로 $O(N)$에 트리를 실제로 구성한 후
- HLD 전처리를 $O(N)$에 수행하면
총 시간 복잡도는 $O \left( N \lg N \right)$이다.
또한, 각 쿼리에 대하여
- 높이를 바꾸기 전에, $O \left( \lg^2 N \right)$에 그 전봇대와 교차하는 트리 정점의 가중치를 $1$ 감소한 후
- 높이를 바꾼 전봇대가 트리 정점과 교차하는, 그러한 정점이 이루는 경로의 양 끝 정점을 $O \left( \lg N \right)$에 찾고
- $O \left( \lg^2 N \right)$에 그 경로의 가중치를 $1$ 증가하고
- 현재 전선으로 연결할 수 있는 두 불변 전봇대 쌍의 개수를 $O \left( \lg^2 N \right)$에 알아내며
- 두 가변 전봇대 쌍과 불변-가변 전봇대 쌍의 개수를 $O \left( Q \right)$에 세면
$O \left( \lg^2 N + Q \right)$의 시간 복잡도로 처리할 수 있다.
따라서, 전체 시간 복잡도는 $O \left( N \lg N + Q \lg^2 N + Q^2 \right)$이다.
기존 스택 알고리즘의 전체 시간 복잡도 $O \left( NQ \right)$보다는 빠르다고 말할 수 있다.
하지만, 여기서 약간의 처리만으로 복잡도를 더 낮출 수 있다.
제곱근 분할법
앞에서 논의하길, $O \left( N \lg N + Q \lg^2 N + Q^2 \right)$의 복잡도로 $Q$개의 쿼리를 처리할 수 있었다.
만약, $Q$개의 쿼리를 $D$개씩 분할하여, 전체 문제를 $\displaystyle \frac{Q}{D}$번에 걸쳐 해결하면 시간 복잡도가 어떻게 될까?
좌표 압축은 오직 한 번만 수행해도 된다는 점에 유의하여, 단순한 사칙연산을 적용하면
\[O \left( N \lg N + \frac{Q}{D} \times \left( N + D \lg^2 N + D^2 \right) \right) = O \left( N \lg N + \frac{QN}{D} + Q \lg^2 N + QD \right)\]가 총 시간 복잡도가 됨을 알 수 있다.
여기서, $D = \sqrt{N}$일 때, 위의 복잡도가 최소가 되며, 이는 $O \left( N \lg N + Q \sqrt{N} \right)$이다.
정리하면, 쿼리를 $\sqrt{N}$개씩 나누어 처리하면, 각 쿼리를 $O \left( \sqrt{N} \right)$의 복잡도로 해결할 수 있다!
1 | |
결론
트리는 다방면에서 복잡한 현상을 단순화할 때 주로 사용되며, 여러 좋은 성질을 가지고 있기에 알고리즘 분야에서 애용된다.
우리는 두 가지 종류의 쿼리를 요구하는 복잡한 수열 문제를 트리에서의 연산으로 해석한 후 제곱근 분할법을 적용하여 효율적으로 해결하는 방법을 알아내었다.
여기서 다루지는 않았지만, 쿼리 시각에 대한 분할 정복 기법을 적용하면 쿼리당 시간 복잡도를 $O \left( \lg N \lg Q \right)$까지 개선할 수 있으며, 이는 추후에 다룰 것이다.
이렇듯 복잡한 문제를 가시화한 후, 잘 알려진 다른 문제로 환원하는 작업은 어려울 수 있으나 우리에게 더 깊은 통찰력을 줄 수 있다.
이번 포스트에서 다룬 문제는 가까운 시일 내에 BOJ에 업로드될 예정이다.